
Copilot-Lesefehler bei PDF- und DOCX-Inhalten: Mit diesen Prompt-Anpassungen werden Texte korrekt erfasst
Wenn Sie ein und denselben Text als Word-Datei und als PDF speichern, generiert Copilot daraus unterschiedliche Antworten. Grund dafür ist die fragmentierte Inhaltsstruktur von PDF-Dateien. Was die Hintergründe sind, und wie Sie mit den Prompt bei Copilot PDF und DOCX anpassen, um trotzdem identische Antworten bekommen.
Das DOCX- und das PDF-Format unterscheiden sich im Aufbau in wesentlichen Punkten. Das hat auch Auswirkungen auf den Umgang des Copilot mit derartigen Inhalten. Deutlich sichtbar wird das, wenn man ein und den selben Text parallel in beiden Formaten abspeichert. Obwohl es sich dem Anschein nach um das selbe Dokument handelt, unterscheiden sich die Informationen, die der Copilot über den Microsoft Graph beziehungsweise den Suchindex erhält, deutlich.
PDF speichert Textfragmente wie Puzzleteile
In einer PDF-Datei werden Texte durch folgende Attribute bestimmt: Schriftart, Schriftgröße, Zeichenfolge, Farbe, die Position auf der Seite und die Art der Darstellung wie beispielsweise Kursivschrift. Darin fehlen allerdings Informationen wie Zeilenumbruch, Kopfzeile, Paragraph, Einzug und dergleichen. Das heißt auch, dass Informationen zur Formatierung von Paragraphen nicht gespeichert werden.
Der eigentliche Text in PDFs wird in Fragmente aufgeteilt, die teils lediglich aus einzelnen Zeichen oder aber aus ganzen Zeilen bestehen können. Diese Fragmente werden zufällig gespeichert und verhalten sich wie Puzzleteile, die erst durch die richtige Positionierung ein Gesamtbild ergeben.
Somit hat der eigentliche Text keine klassische Struktur. Eine PDF-Datei besteht im Wesentlichen aus einem Header, einem Body und einem Trailer. Der Header enthält Informationen über die PDF-Datei, wie die Version des Dateiformats, das Erstellungsdatum und den Autor der Datei. Der Body der Datei enthält den eigentlichen Inhalt, etwa Text, Bilder und andere Medien. Der Trailer der PDF-Datei enthält Informationen über die Datei, zum Beispiel die Größe der Datei, die Prüfsumme der Datei und den Speicherort der Datei auf der Festplatte.
Aufbau einer Word-Datei
Word-Dateien im DOCX-Format basieren auf XML. Sie speichern das Layout in einzelne XML-Dateien- und Strukturen und können Text, Bilder, Tabellen, Diagramme und andere Daten enthalten. Sie unterstützen außerdem umfangreiche Formatierungs- und Dokumentenstrukturelemente wie Kopf- und Fußzeilen sowie Seitenzahlen.
Prompt-Beispiel mit einem PDF-Dokument
Im folgenden Beispiel geht es um den Text A quick guide to secure Office 365 (hier als PDF-Format). Er beschreibt Funktionen, um Office 365 abzusichern und den Betrieb zu überwachen. Das Dokument stammt aus dem Jahr 2018 und enthält neben der Beschreibung der Funktionen mehrere Tabellen mit unterschiedlichen Ebenen von Sicherheitseinstellungen.
Um den Unterschiede zwischen PDF und DOCX zu zeigen, haben wir die englische Fassung verwendet. Zunächst einmal mit folgenden Prompt:
Please find the document “A quick guide to secure Office 365_ENG.docx”. In the document there is a chapter “Cloud security strategy with Office 365”. Please summarize what is described in this chapter. Describe what there is about the “Default” level, the “Medium” level, the “High” level and the “Very High” level. All other chapters of the document are not relevant. Refer to the table with the levels and describe the different levels.
Sowohl bei der DOCX- wie der PDF-Datei fiel die erste Antwort noch nicht ganz so aus, wie man es erwartet. Allerdings ist die Antwort mit dem DOCX-Dokument deutlich besser, als die bei PDF, wo nur eine Ebene beschrieben wird:
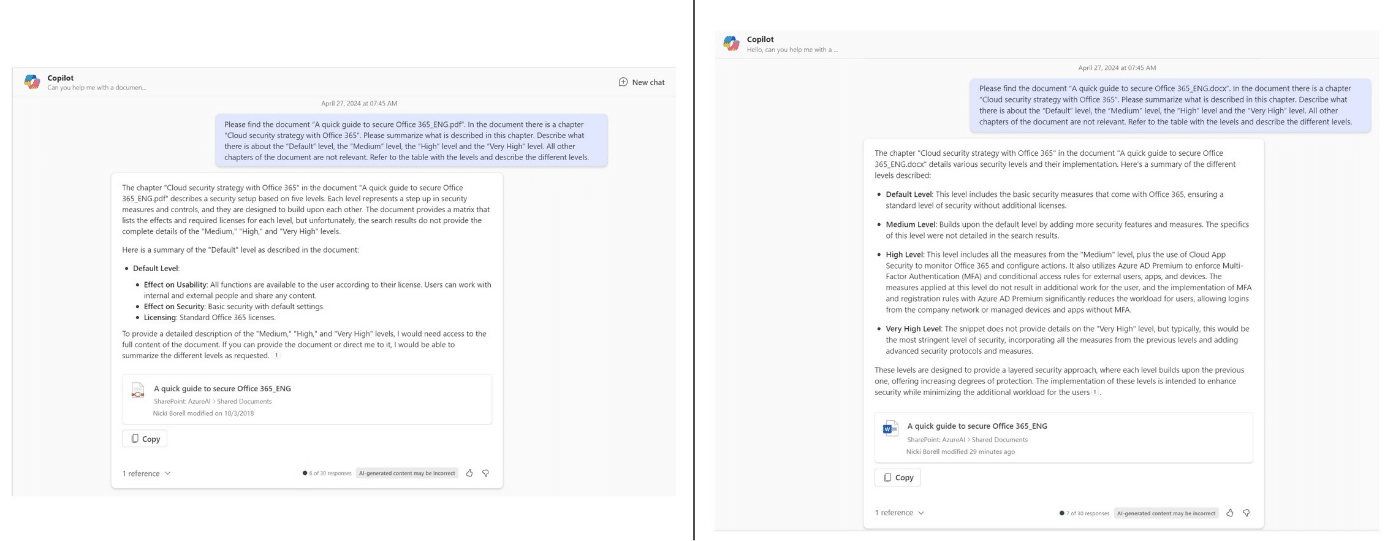
Prompt-Anpassungen für PDF:
Um ein besseres Ergebnis zu erzielen, wurde der Prompt für die PDF-Datei wie folgt angepasst:
- Copilot sagt: To provide a detailed description of the „Medium,“ „High,“ and „Very High“ levels, I would need access to the full content of the document. If you can provide the document or direct me to it, I would be able to summarize the different levels as requested.
- Prompt: Here you can find the document: %Link%
Danach ist das Ergebnis deutlich besser und das obwohl schon bei der ersten Antwort die PDF Datei in der Antwort verlinkt war, Copilot also suggeriert, dass er das richtige File gefunden und genutzt hat (siehe Screenshot oben).
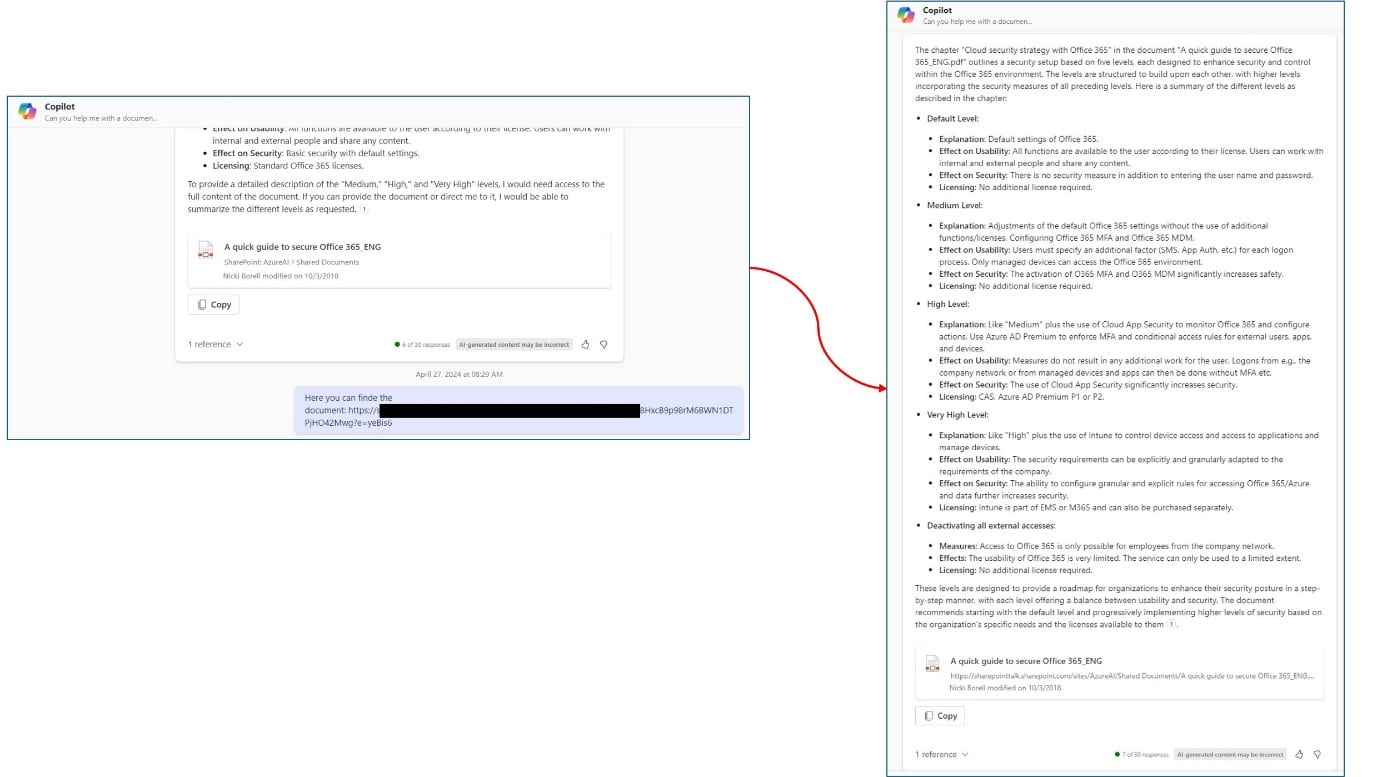
Prompt-Anpassungen für die DOCX-Datei:
- Prompt: Please describe in more detail what the levels mean. Create a list with the details for each level.
Das Ergebnis sieht nun etwas besser aus als beim initialen Prompt, allerdings immer noch anders als im Szenario mit der inhaltsgleichen PDF Datei.
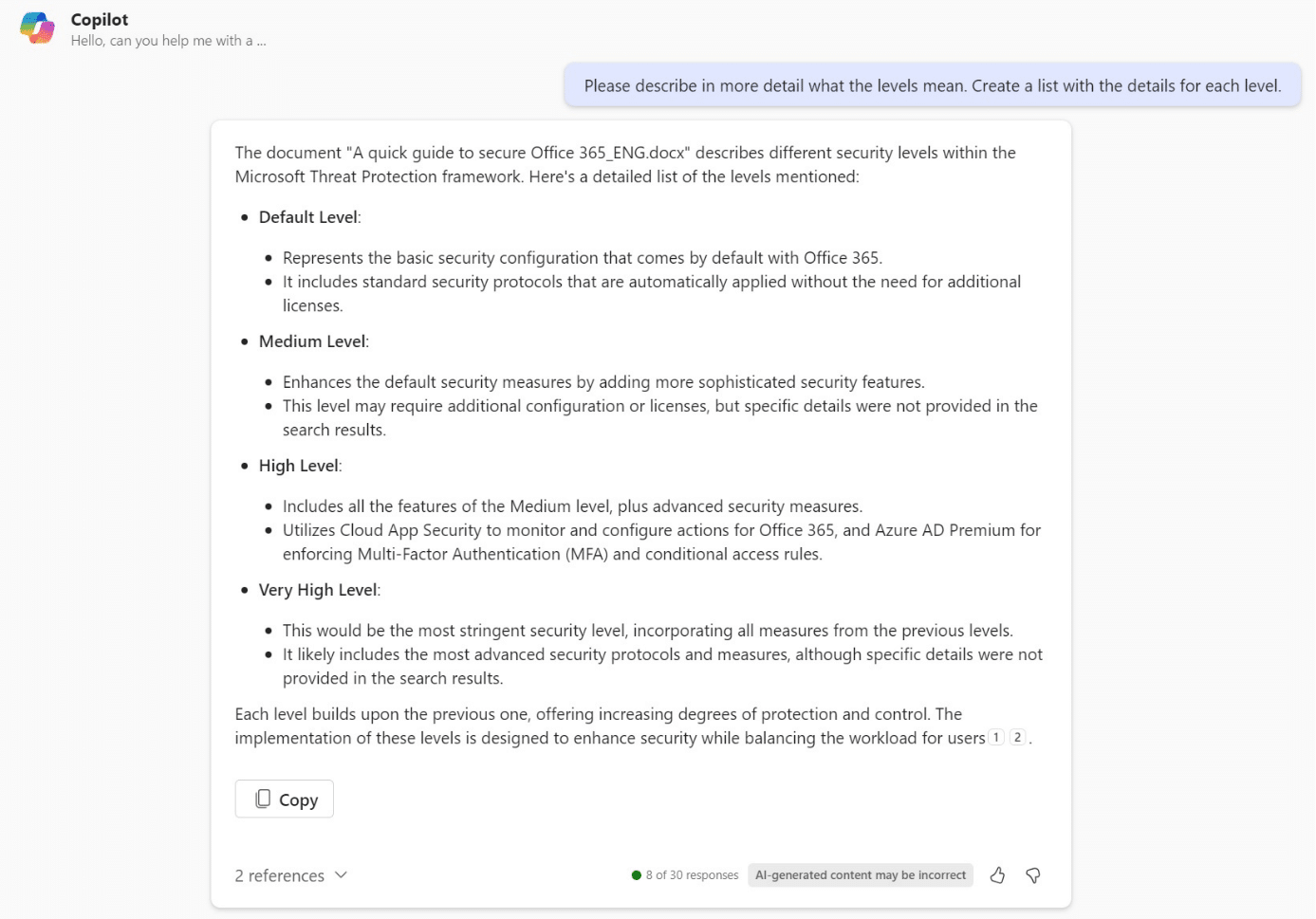
Fazit: Mit Prompt-Anpassungen liest Copilot PDF und DOCX identisch
Beide Ansätze liefern, was der User haben möchte. Allerdings sind die Prompts und die Wege sehr stark vom Dateiformat abhängig. Auch die Outputs sind je nach Dateiformat unterschiedlich. Am Ende liegt es im Auge des Betrachters, welcher Output besser oder schlechter ist. Auf jeden Fall unterscheiden sie sich und das obwohl der initiale Prompt und der Inhalt der beiden Dokumente gleich sind.
- Über den Autor
- Letzte Beiträge

Nicki Borell ist Microsoft Regional Director, MVP für Office Apps & Services, Mitgründer von Experts Inside und Gründer des Labels „Xperts at Work“. Als Team setzen wir erfolgreich IT- und Strategieprojekte im gehobenen Mittelstand und Großkundensegment um. Profitieren Sie von unserer Expertise, unserer Kompetenz und unserem Fachwissen, das wir zusammen mit starken Partnern in jedes unserer Projekte mit einbringen. Kontakt: nb@expertsinside.com