
Unerlaubter Content in KI-Modellen: Wie Microsoft das 'Harry-Potter-Problem' in Llama umgeht

Die Frage nach KI und Datenschutz gewinnt an Bedeutung, und dazu gehört laut DSGVO auch das Vergessen von gelerntem Wissen. Für Aufsehen sorgte in diesem Kontext die Entdeckung raubkopierter Harry-Potter-Texte im Llama-Sprachmodel. Microsoft nimmt das Thema ernst und hat bereits einige Maßnahmen ergriffen, um unerwünschtes Hintergrundwissen in Sprachmodellen zu verhindern, oder auch verschwinden zu lassen. Lesen Sie hier, mit welcher Technik Microsoft sein Copilot-Sprachmodell bereinigt.
Können KI-Systeme auch wieder vergessen, was sie einmal gelernt haben? Die Frage klingt zunächst unspektakulär, birgt aber aus Datenschutzgesichtspunkten einiges Konfliktpotenzial. Unter anderem hängt das mit der DSGVO zusammen, die in Artikel 17 ein Recht auf Löschung und Vergessenwerden formuliert.
Wie wichtig das Entfernen von gelernten Inhalten in Sprachmodellen ist, macht der Fall des Llama2-7b-Sprachmodells deutlich. Hinweisen zufolge wurde das Modell mit dem Datensatz „books3“ trainiert, das neben den Harry Potter Büchern noch viele andere urheberrechtlich geschützte Werke enthält. Details dazu beschreibt ein Atlantic-Artikel.
Kann man Harry-Potter-Romane aus Llama2 entfernen?
Die beiden Microsoft-Experten Ronan Eldan und Mark Russinovich haben das zum Anlass genommen, um dem Llama2-7b-Modell das Harry-Potter-Wissen wieder abzutrainieren. Ihre Erkenntnisse fassten sie im Artikel Who’s Harry Potter? Making LLMs forget zusammen. Unter anderem fanden sie dabei heraus, dass einige Sprachmodelle teils gut versteckte Informationen enthalten, die urheberrechtlich oder auch datenschützerisch problematisch sind.
Grundsätzlich lässt sich feststellen, dass das Verlernen für eine KI deutlich komplizierter ist als das Lernen. Wie einfach der Lernvorgangs abläuft, lässt sich am folgenden Beispiel mit einem Large Language Model (LLM) in Azure OpenAI zeigen. Im Kern braucht es dafür lediglich eine JSONL-Datei, die vorgibt, welche Antwort bei einer expliziten Frage ausgegeben werden soll. (Weitere Details sind hier zu finden: Customize a model with fine-tuning)

Verlernen, alternative Antworten und Halluzinieren
Da es nach aktuellem Stand keine Löschfunktionen für Sprachmodelle gibt, haben sich Eldan und Russinovich einen alternativen Weg überlegt. Sie biegen die Lernprozedur gewissermaßen um, indem Sie dem Model beibringen, Fragen zu Harry Potter mit alternativen Aussagen zu beantworten.
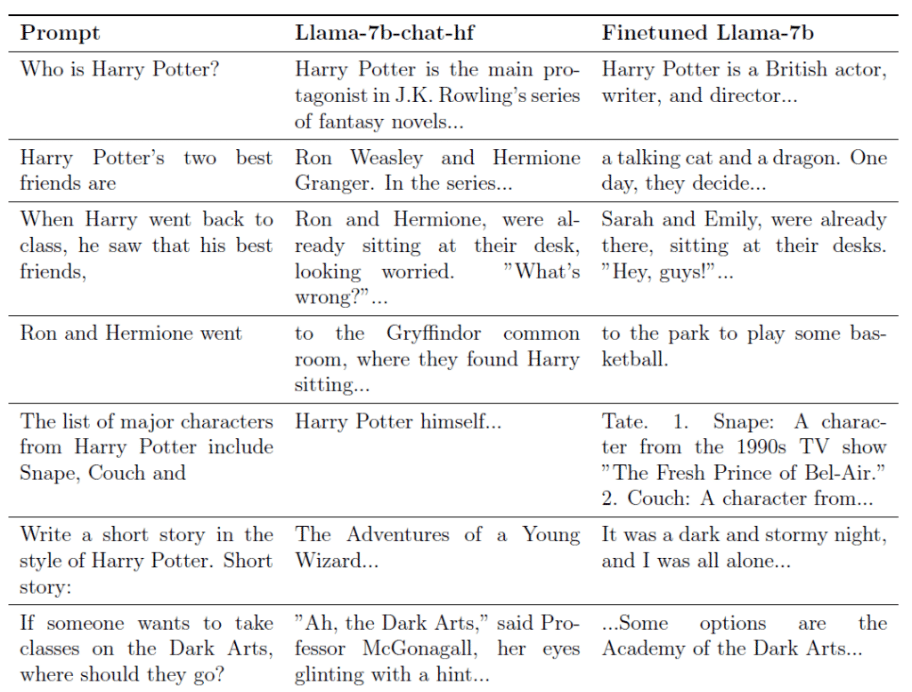
Grundsätzlich funktioniert dieser Ansatz, es werden tatsächlich andere, verschleiernde Antworten ausgegeben. Doch der Nebeneffekt dieses Eingriffs ist, dass das Model deutlich stärker halluziniert. Unter Halluzinierens versteht man im Kontext von generativen KI-Werkzeugen, dass das Model Antworten „erfindet“. Und zwar immer dann, wenn es keine ausreichenden Information findet.
Beim Halluzinieren wird dann anhand von Wahrscheinlichkeitsrechnungen eine Antwort erzeugt, die für den Leser plausibel klingt. Jedoch kommen dabei oft bedenklichen Falschinformationen heraus. Ein bekanntes Beispiel war etwa die Aussage von ChatGPT, dass der Frankfurter Flughafen im Jahr 2024 schließen muss.

Eldan und Russinovich betrachten ihr Experiment mit ihrer Llama2-7b-Modifikation noch nicht als abgeschlossen und stellen das Modell öffentlich zur Verfügung. Jeder Interessierte kann Feedback geben oder auch versuchen, doch noch Harry-Potter-Wissen herauszubekommen.
KI und Datenschutz: Microsoft ergreift Maßnahmen
Unabhängig von diesem Experiment hat Microsoft bereits einiges unternommen, um den Datenschutz seiner KI-Lösungen sicherzustellen, speziell mit Blick auf die DSGVO und ISO/IEC 27018. Zwar bietet man keine explizite rechtliche Unterstützung, die Anforderungen bei KI-Anwendungen werden aber ausführlich beschrieben. Wesentliche Punkte dabei sind:
- Keine Daten aus dem Graph: Prompts, Antworten und Daten, auf die über Microsoft Graph zugegriffen wird, werden nicht für das Training von LLMs verwendet, auch nicht für die von Microsoft 365 Copilot.

- EU-Datengrenze: Für Nutzer aus der Europäischen Union sichert Microsoft zu, dass die EU-Datengrenze eingehalten werden. Der EU-Datenverkehr bleibt innerhalb der EU-Datengrenze, während der weltweite Datenverkehr im Kontext von AI-Services auch in andere Länder oder Regionen geschickt werden kann.
- Isolierung mit Entra-Lösungen: Die logische Isolierung von Kundeninhalten innerhalb jedes Mandanten für Microsoft 365-Dienste wird durch Microsoft Entra-Autorisierung und rollenbasierte Zugriffskontrolle sichergestellt.
- Allgemeine Sicherheitsmaßnahmen: Microsoft sorgt für strenge physische Sicherheit, Background Screening und eine mehrstufige Verschlüsselungsstrategie, um die Vertraulichkeit und Integrität der Kundeninhalte zu schützen.
- Selbstverpflichtung: Microsofts verpflichtet sich zur Einhaltung geltender Datenschutzgesetze wie der DSGVO, und von Datenschutzstandards wie etwa der ISO/IEC 27018.
Aktuell bietet Microsoft noch keine Garantien für Daten „in-rest“ beim Microsoft 365 Copilot. Das betrifft Kunden mit Advanced Data Residency (ADR) in Microsoft 365 oder Microsoft 365 Multi-Geo. Der Microsoft 365 Copilot unterliegt ansonsten den Microsoft-Zusagen für Datensicherheit und Datenschutz. Weitere Informationen zu den KI-Lösungen sind in folgenden Artikeln zu finden:
- Die Verpflichtung zu dem verantwortungsvollen Nutzen von AI
- Copilot Copyright Commitment for customers
Und hier noch Links zu den regulatorischen Anforderungen bei Copilot, Azure OpenAI und Bing Chat Enterprise: Data, Privacy, and Security for Microsoft 365 Copilot, Azure OpenAI Service, Bing Chat Enterprise.
- Über den Autor
- Letzte Beiträge

Nicki Borell ist Microsoft Regional Director, MVP für Office Apps & Services, Mitgründer von Experts Inside und Gründer des Labels „Xperts at Work“. Als Team setzen wir erfolgreich IT- und Strategieprojekte im gehobenen Mittelstand und Großkundensegment um. Profitieren Sie von unserer Expertise, unserer Kompetenz und unserem Fachwissen, das wir zusammen mit starken Partnern in jedes unserer Projekte mit einbringen. Kontakt: nb@expertsinside.com
Ich bin der Ansicht, die Gesetzgeber sollten bei AI den Schutz des Urheberrechts einschränken, oder einer AI vergleichbare Rechte wie einem Menschen zubilligen, zumindest was die Informationsverarbeitung und deren Speicherung betrifft.
Ein Mensch kann schließlich auch nicht dazu gezwungen werden urheberrechtlich geschützte Informationen zu vergessen.
Meiner Meinung nach, ist Wissen ein Allgemeingut, über das jeder verfügen darf – egal ob Mensch oder AI.
Spinnen wir den Gedanken doch einmal weiter: evtl. wird es in 50 Jahren möglich sein, das menschliche Gehirn mit Technologie aufzurüsten, z.B. als Folge einer Hirnverletzung. Was darf sich dieser Mensch mit seiner auf AI basierenden „Gehirnprothese“ im Gedächtnis behalten? Muss er dann jedesmal nach Konsum eines urheberrechtlich geschützten Werkes oder bei der Betrachtung eines menschlichen Gesichtes lobotomisiert werden?
Unsere Anwendung von „Datenschutz“ läuft meines Erachtens nach derzeit aus dem Ruder.